Practical Implementation of Web Crawlers Based on Docker and Pyspider
在本篇笔记中,我将展示基于Docker容器部署Pyspider环境来对“去哪儿旅行”攻略库中的旅游笔记关键信息进行批量爬取。
此次爬取的学习素材来自崔庆才编著的Python3WebSpider以及与Docker容器部署的相关博客。
一、Docker容器中部署Pyspider环境#
想要在Docker容器中部署Pyspider环境,我们首先需要安装和配置好Docker,具体的安装和配置教程各大平台均有,我这里便不再赘述。(还是稍微需要费点功夫的,有兴趣的小伙伴可以试试)
由于我的电脑为Windows系统,所以我选择了将Docker容器配置在Windows系统自带的Linux子系统下,接下来我们打开本地命令行窗口:
1.验证自己的Docker是否已配置至系统环境#
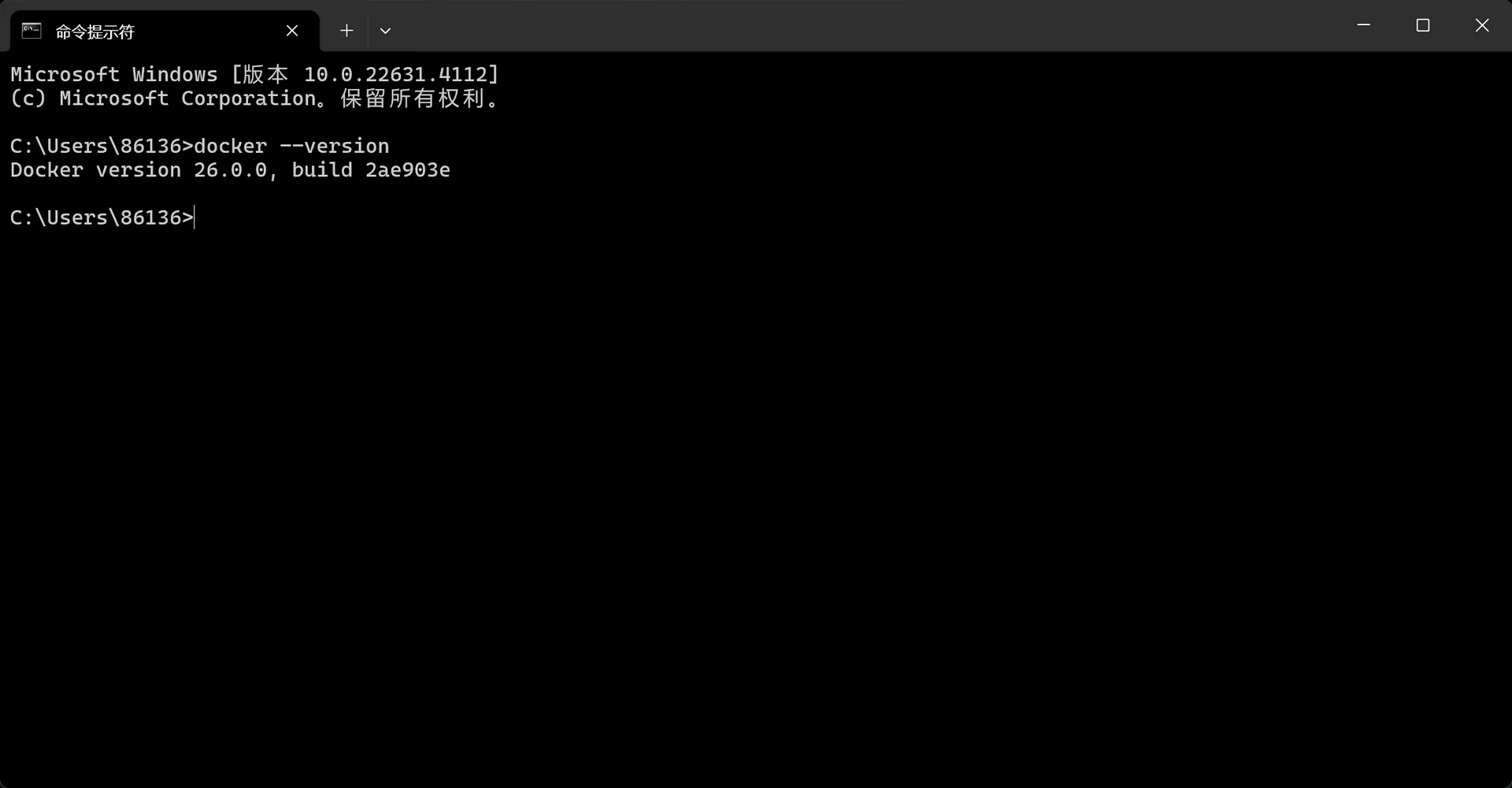
docker --version
如果出现了自己所下载的Docker版本号信息,则证明已成功将其配置至系统环境中:
2.从Docker Hub拉取Pyspider的镜像#
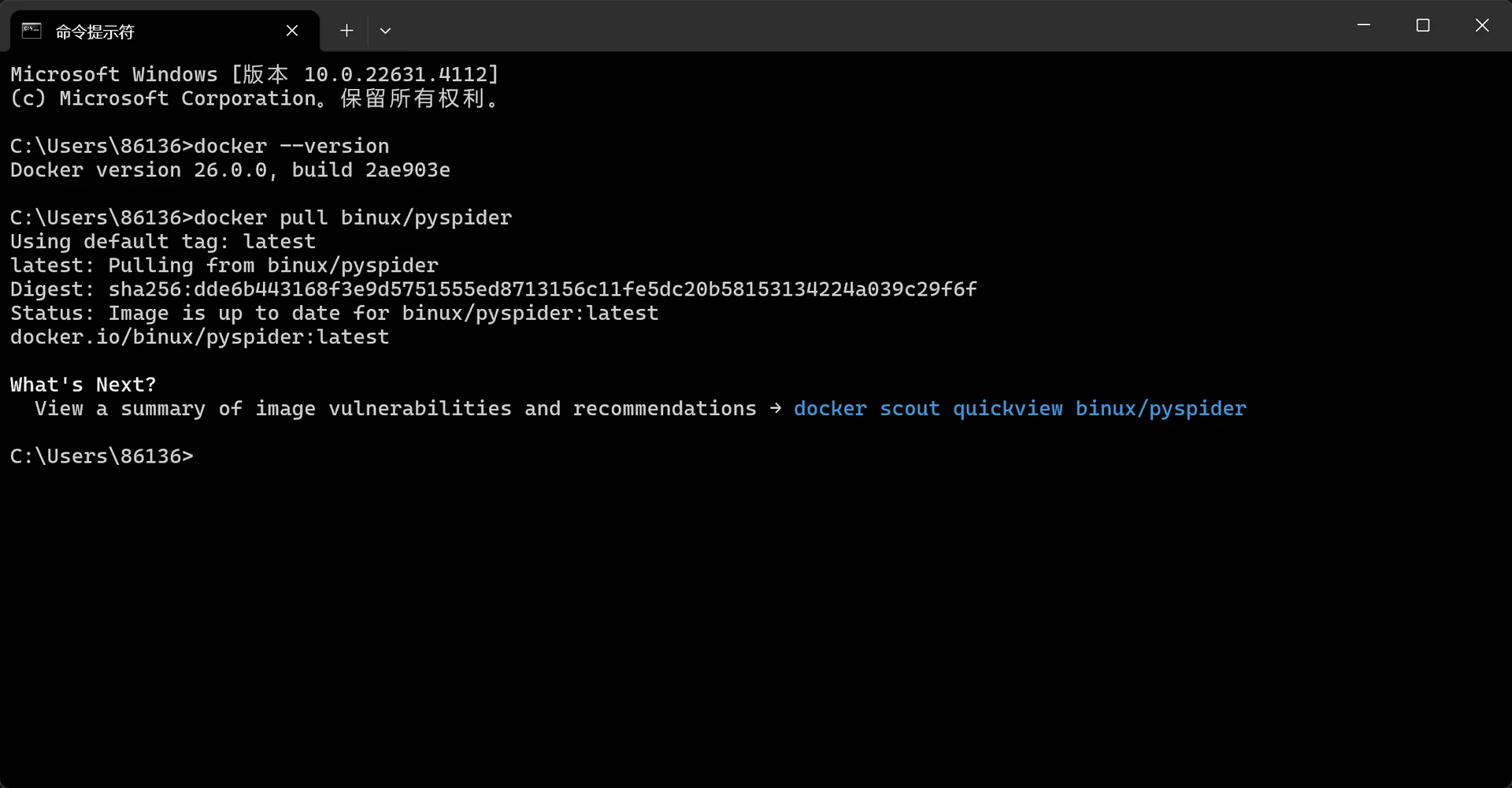
docker pull binux/pyspider
出现类似如下信息即可:
3.创建一个名为pyspider的容器,将本地的5000端口号映射至容器的5000端口号#
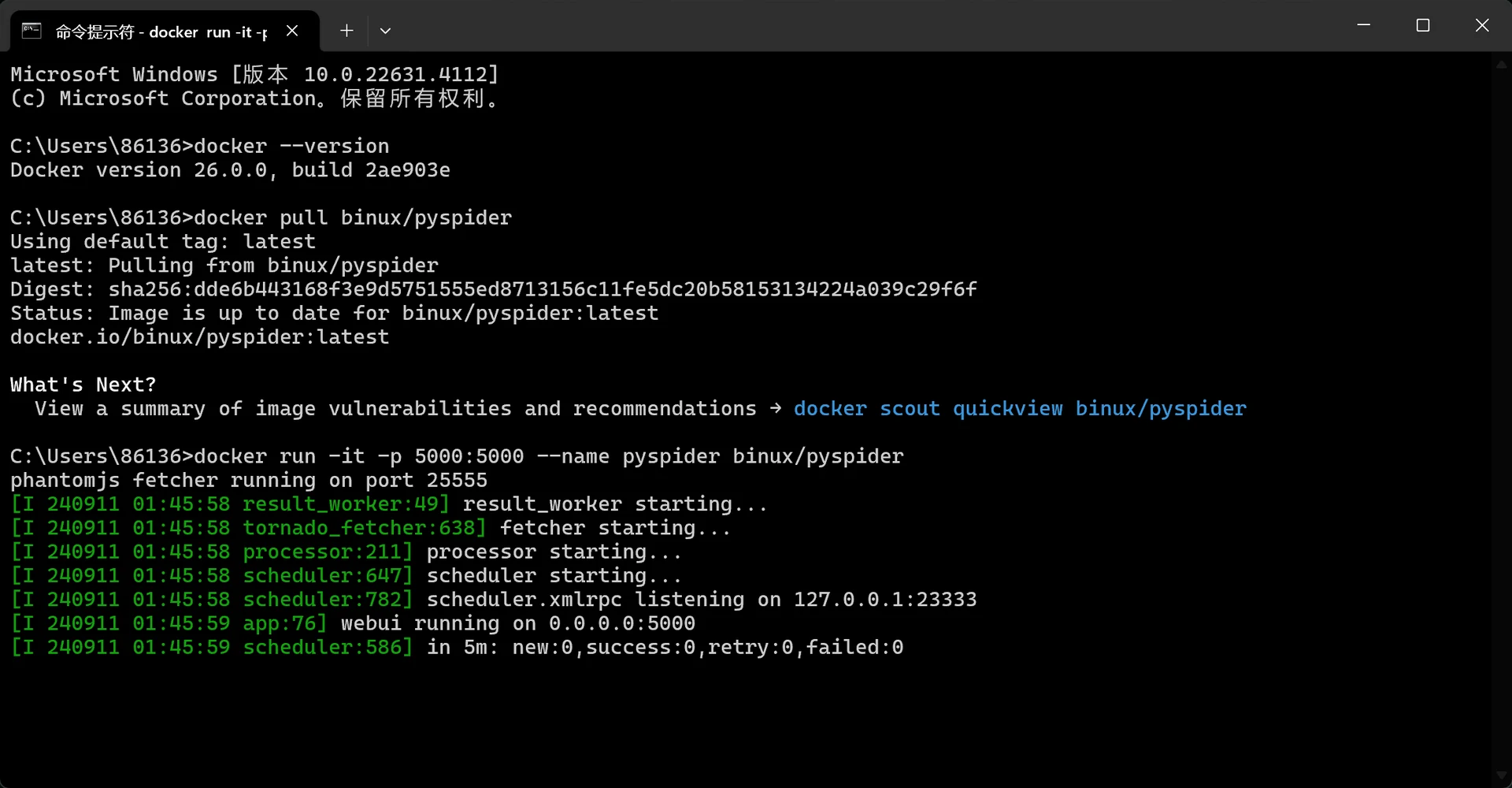
docker run -it -p 5000:5000 --name pyspider binux/pyspider
# 创建的容器名可自定义,符合规范即可
出现类似如下所示的日志状态框即代表容器创建成功并且成功启动了:
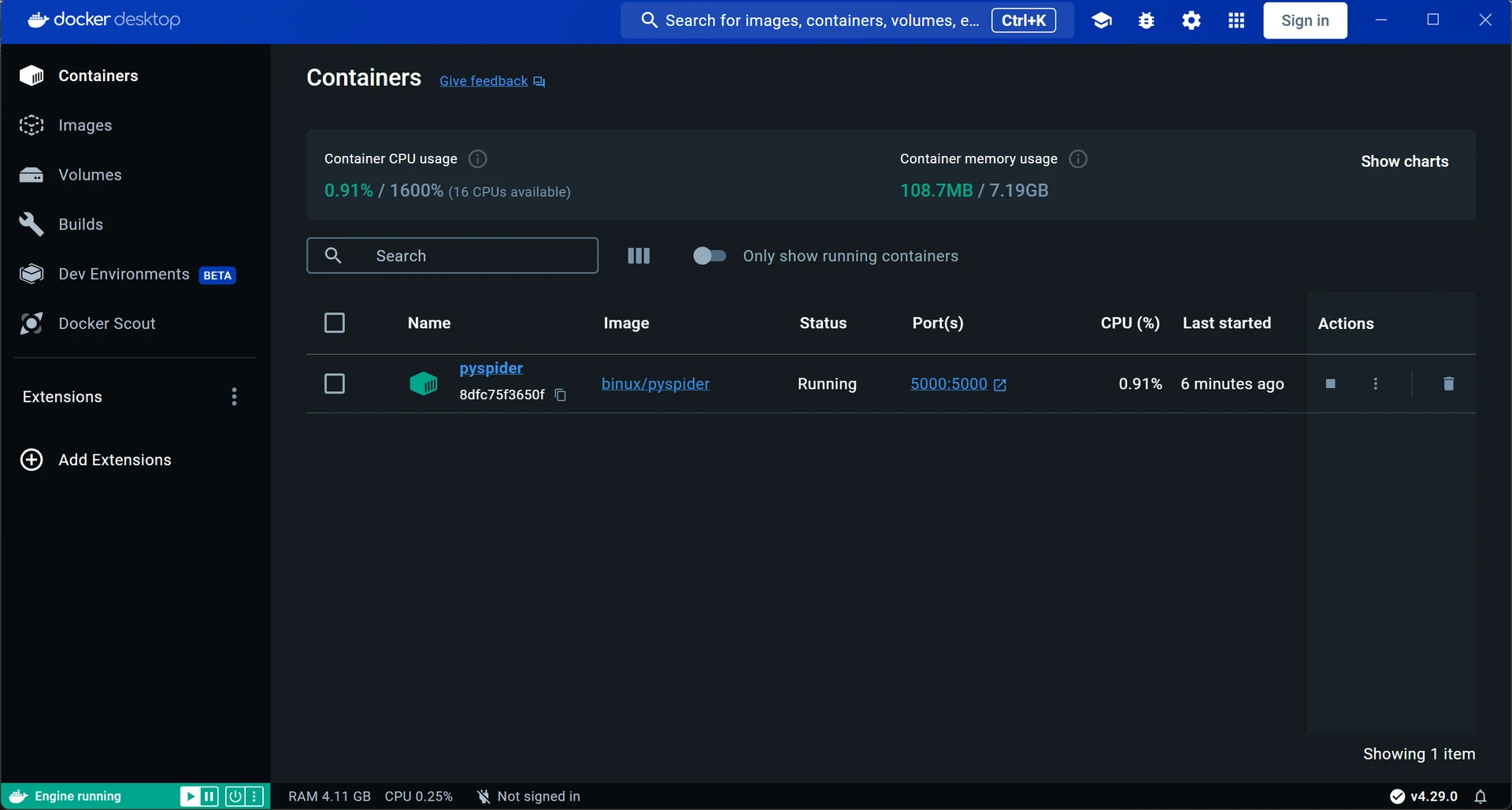
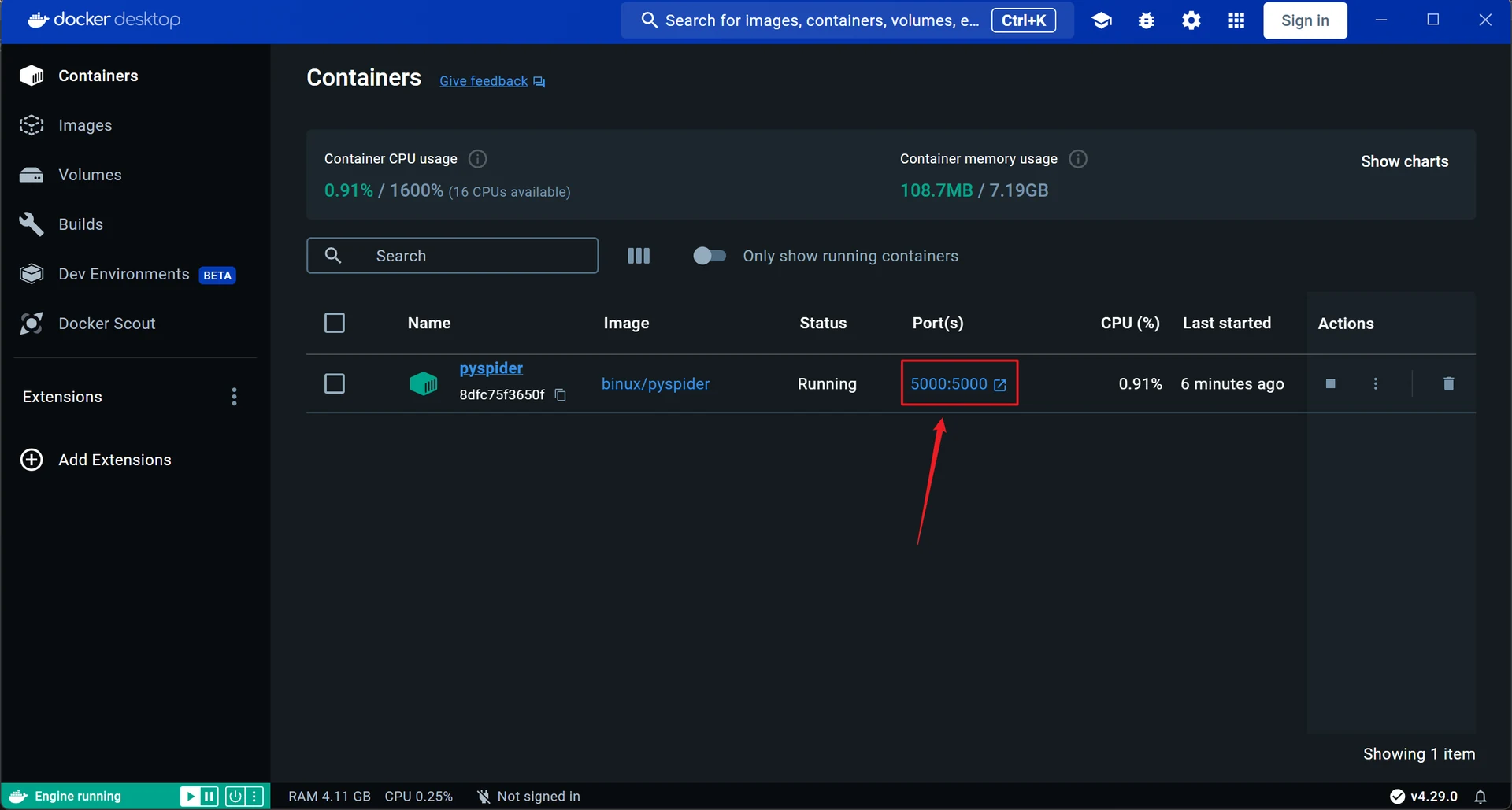
现在我们打开Docker Desktop应用端,会发现其中已经创立了一个正在运行在本地5000端口号的名为pyspider的容器:
二、在Pyspider提供的WebUI上创建项目#
我们在Docker Desktop中点击对应容器的端口号,浏览器便会自动跳转至本地端口5000并显示出Pyspider的WebUI界面:
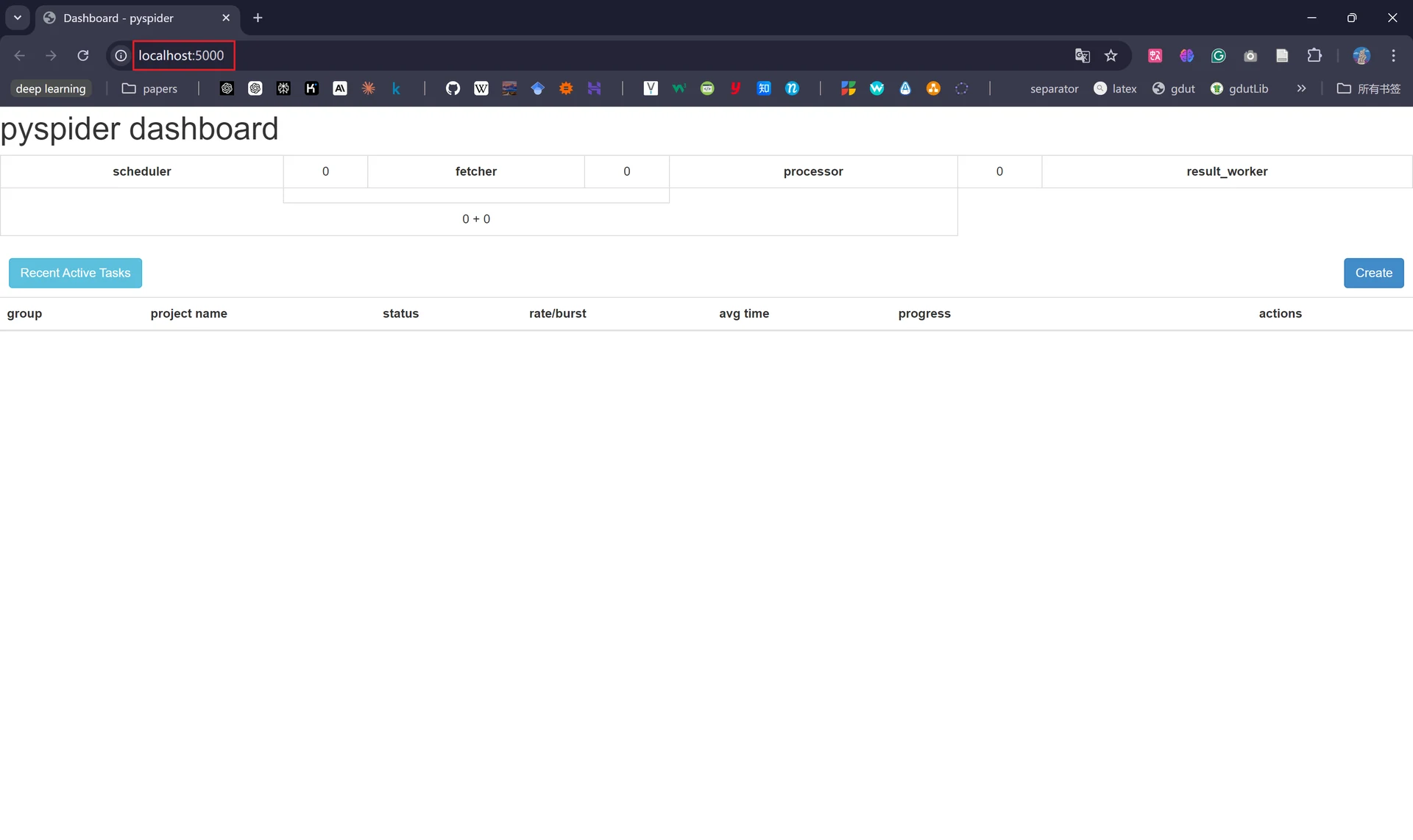
在此页面中,我们可以用来进行项目管理、编写代码、在线调试和监控任务等。
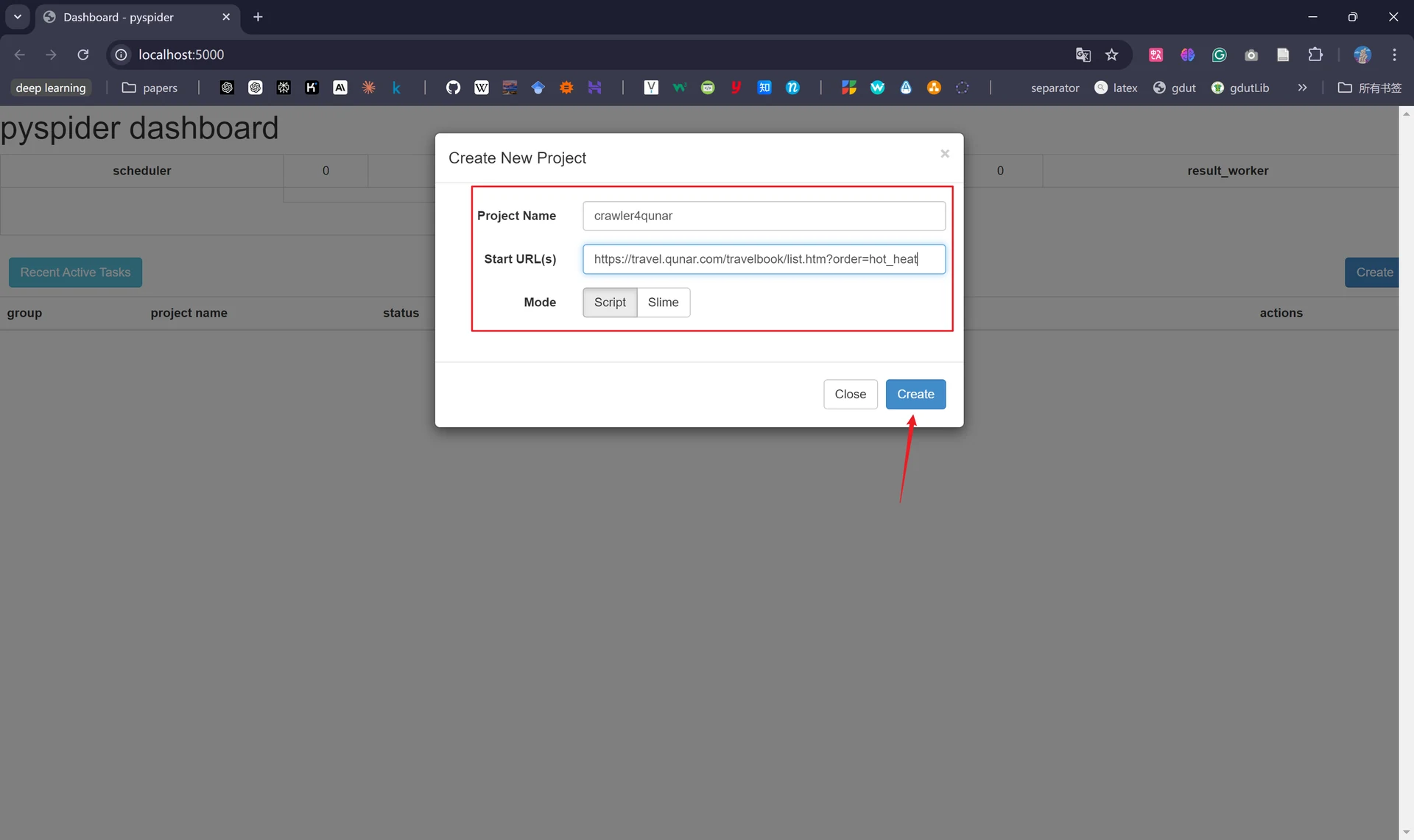
接着我们在页面中点击“Create”创建一个新的项目,其中输入自定义项目名称以及需要爬取的网址链接:
三、crawler4qunar项目分析及实现#
点击“Create”后,接下来我们能看到Pyspider的代码和调试页面,左侧是代码的调试页面,点击“run”可以进行单步调试爬虫程序,左侧下半部分用于预览当前的爬取页面;右侧为代码编辑页面,我们可以在其中直接编辑和保存使用的爬虫代码:
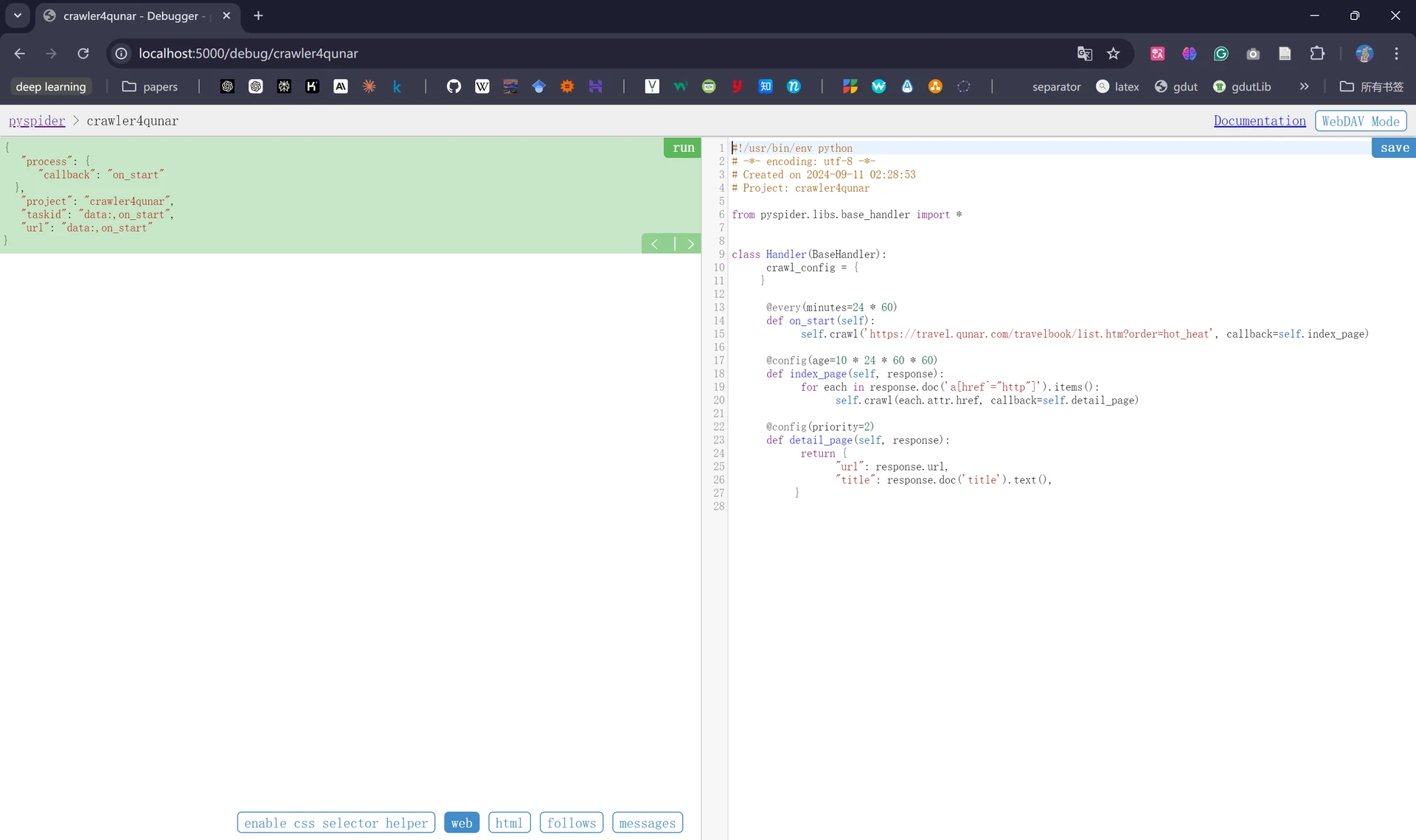
我们先对右侧自动生成的爬虫代码进行分析:
from pyspider.libs.base_handler import *
class Handler(BaseHandler): # Handler类就是整个爬虫的主类,我们在这个类中定义爬取、解析和存储的逻辑
crawl_config = { # crawl_config属性用于统一定义爬虫的Headers、IP代理等,该配置全局生效
}
@every(minutes=24 * 60)
def on_start(self): # on_start()方法为爬虫的爬取入口,该方法通过调用crawl()方法创建爬取请求
self.crawl('https://travel.qunar.com/travelbook/list.htm?order=hot_heat', callback=self.index_page) # 第一个参数为爬取目标的URL,第二个参数callback用于指定页面爬取成功后使用哪个方法进行解析
@config(age=10 * 24 * 60 * 60)
def index_page(self, response): # index_page()方法中的response参数为Pyspider的内置对象,表示爬虫对某个页面执行HTTP请求后的响应内容(如状态码、headers、文本信息等)
for each in response.doc('a[href^="http"]').items(): # 通过调用response中的doc()方法传入对应的CSS选择器,a[href^="http"]代表解析页面中的所有链接,然后遍历链接再次调用crawl()方法
self.crawl(each.attr.href, callback=self.detail_page) # 生成新的爬取请求,当页面爬取成功后调用detail_page()方法进行解析
@config(priority=2)
def detail_page(self, response):# detail_page()方法抓取的为详情页的信息,它只对response对象进行解析,不会生成新的请求,解析后的结果以字典形式返回
return {
"url": response.url,
"title": response.doc('title').text(),
}
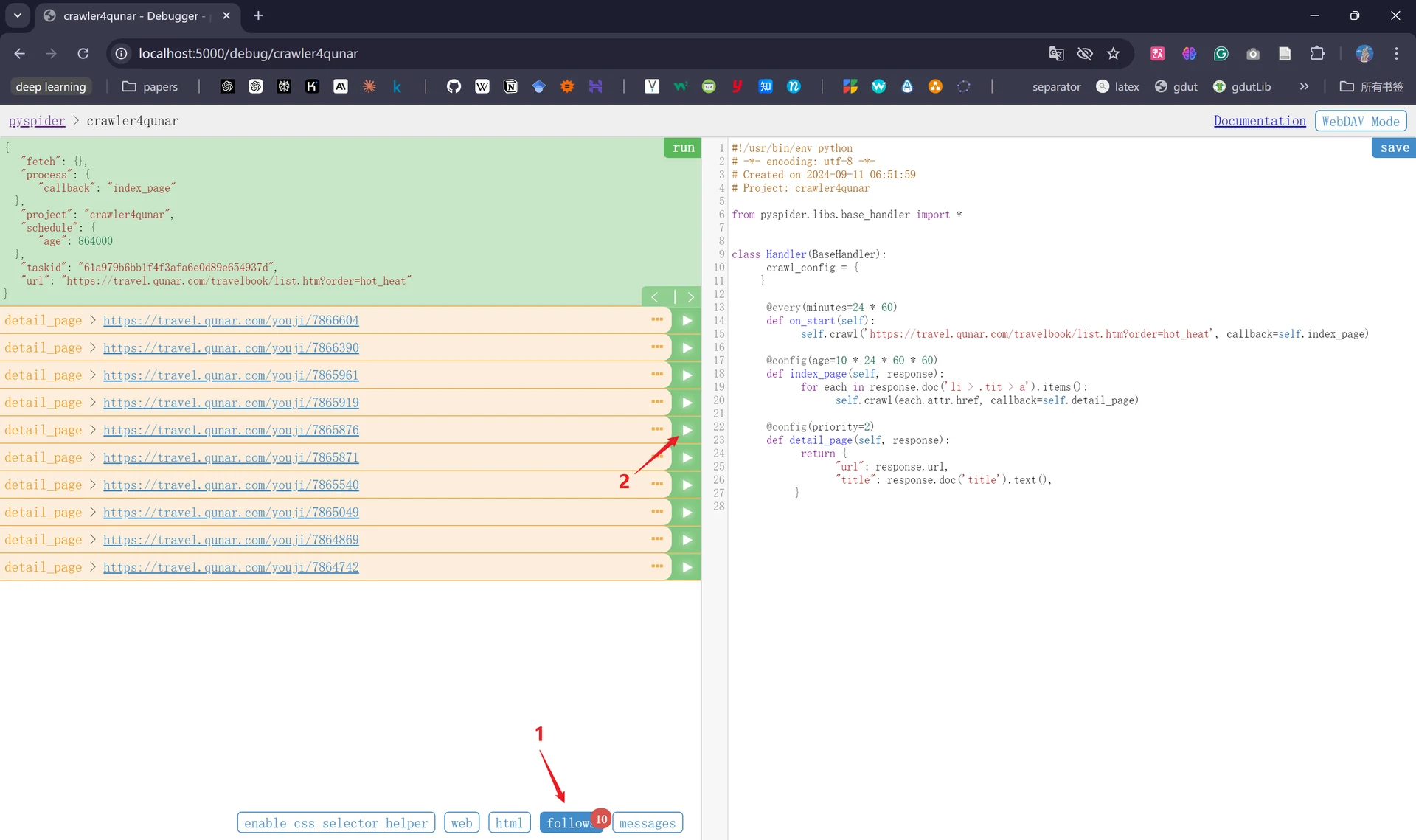
接着我们点击左侧的“run”,会发现下方的“follow”出现数字“1”,代表产生了新的爬取,左上角中的“callback”对应的是“on_start”,说明点击“run”之后执行了on_start()方法。
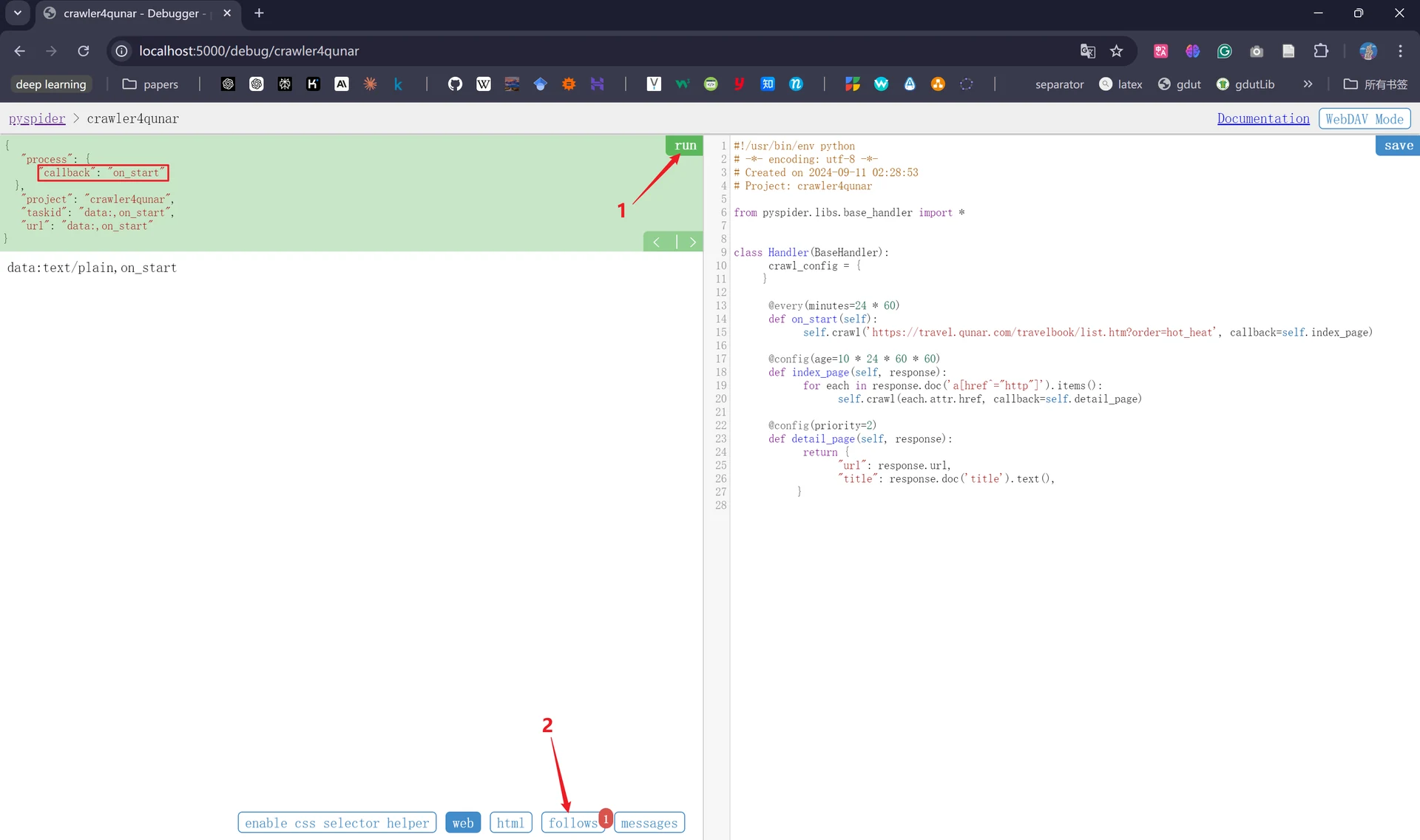
接着我们点击“follows”,发现生成了爬取请求的链接,我们点击该链接右侧的三角形。
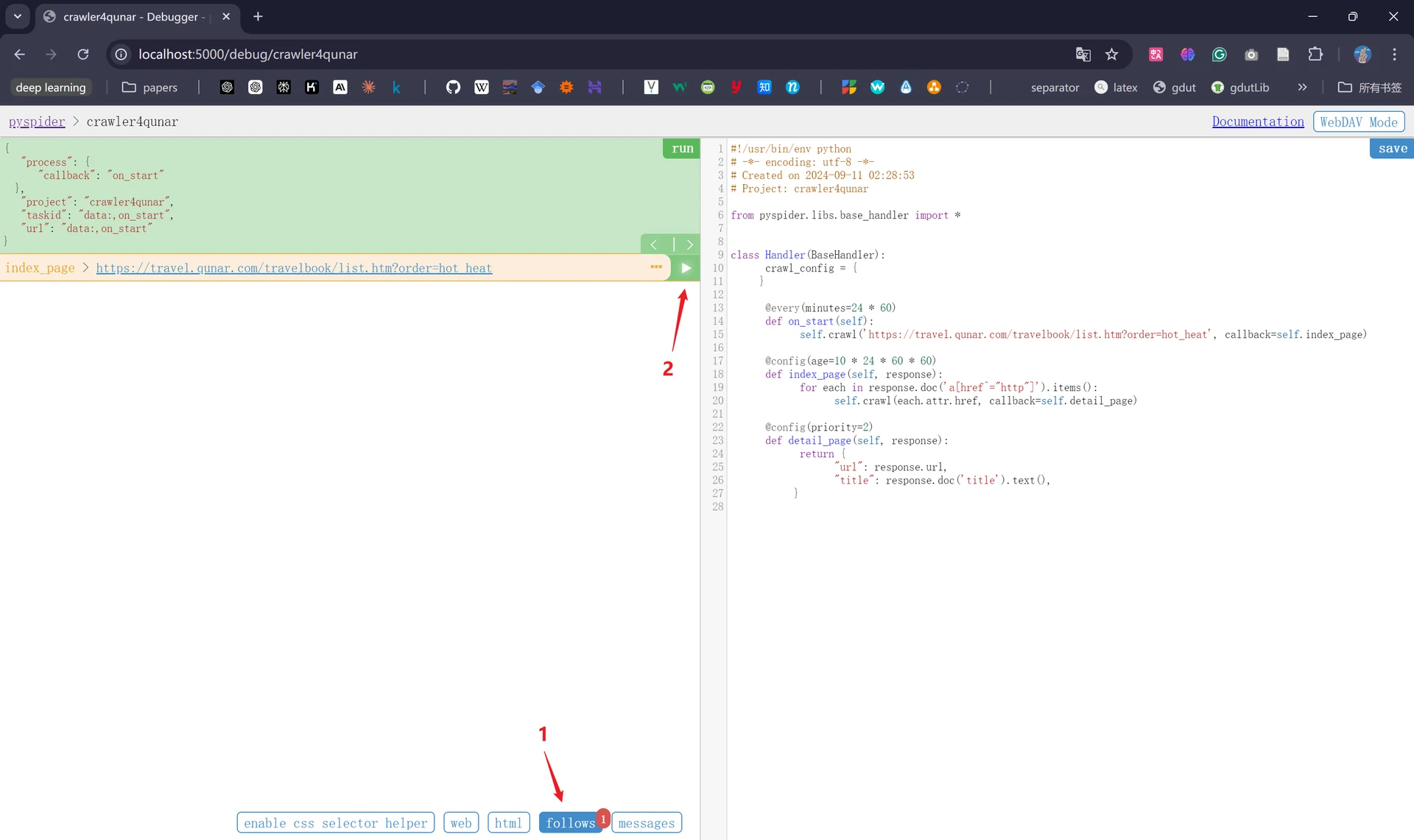
点击三角形后,可能会出现如下报错页面,提示我们该文档为空,我们只需点击“run”刷新几次即可。

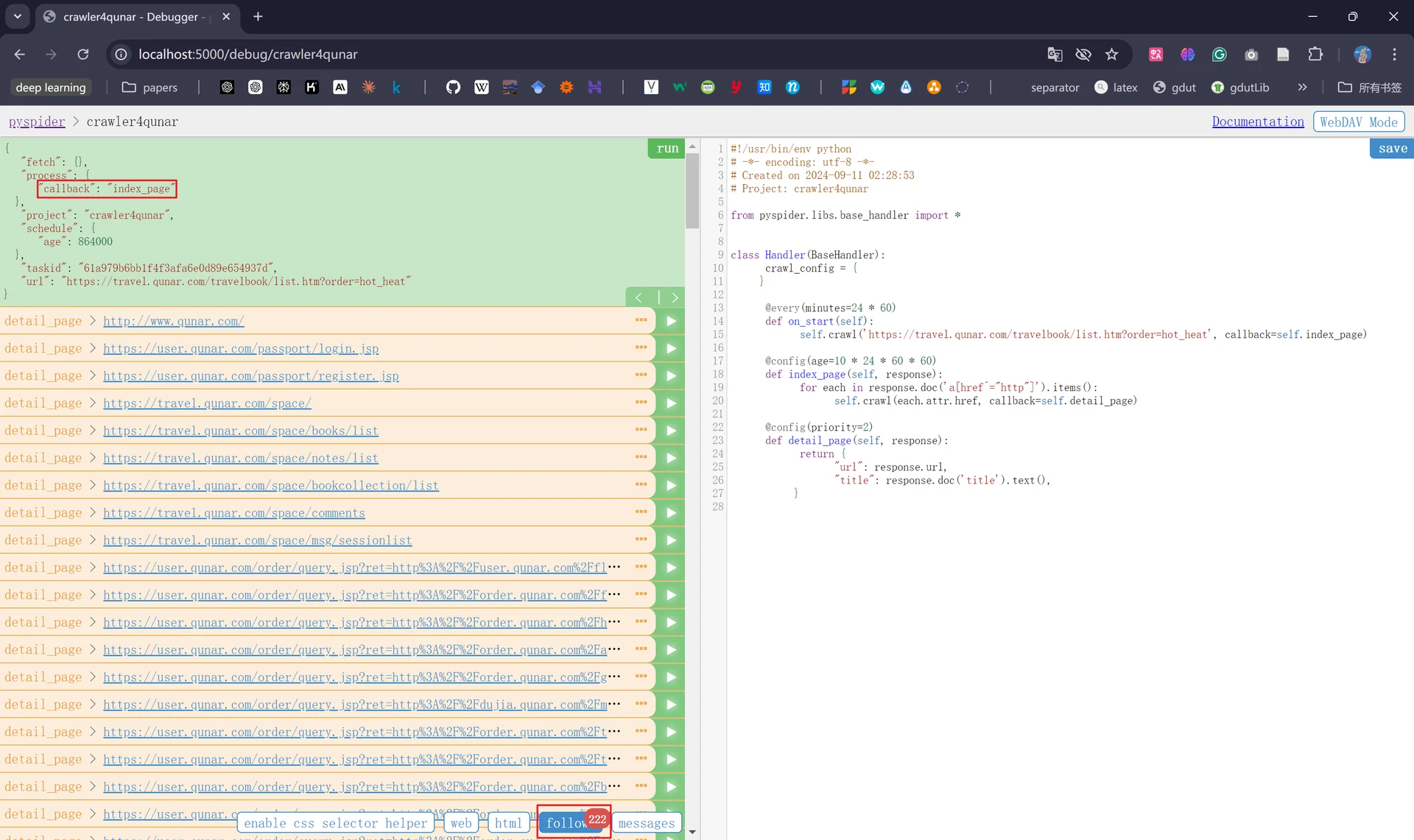
我们此时会发现“callback”已经变为“index_page”,这就代表此时我们运行了index_page()方法;同时下方“follows”出现了“222”的数字,这代表生成了222个新的爬取请求,这222个爬取请求的URL呈现在页面左侧中:
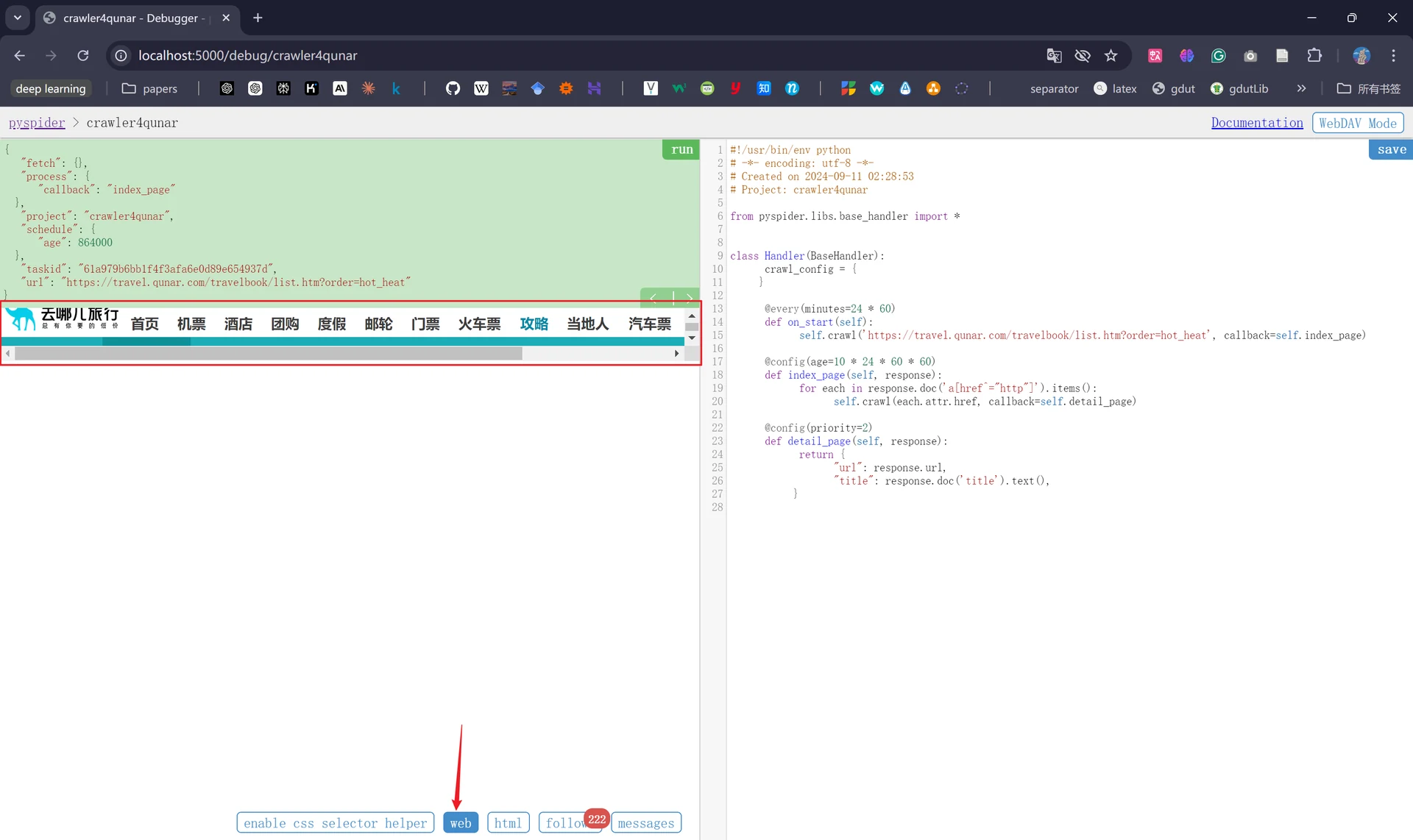
接着我们点击下方的“web”,会发现此时出现了我们爬取的页面(我的页面展开不了,只能以很小的空间拖动查看);点击“html”后会出现页面的源代码:
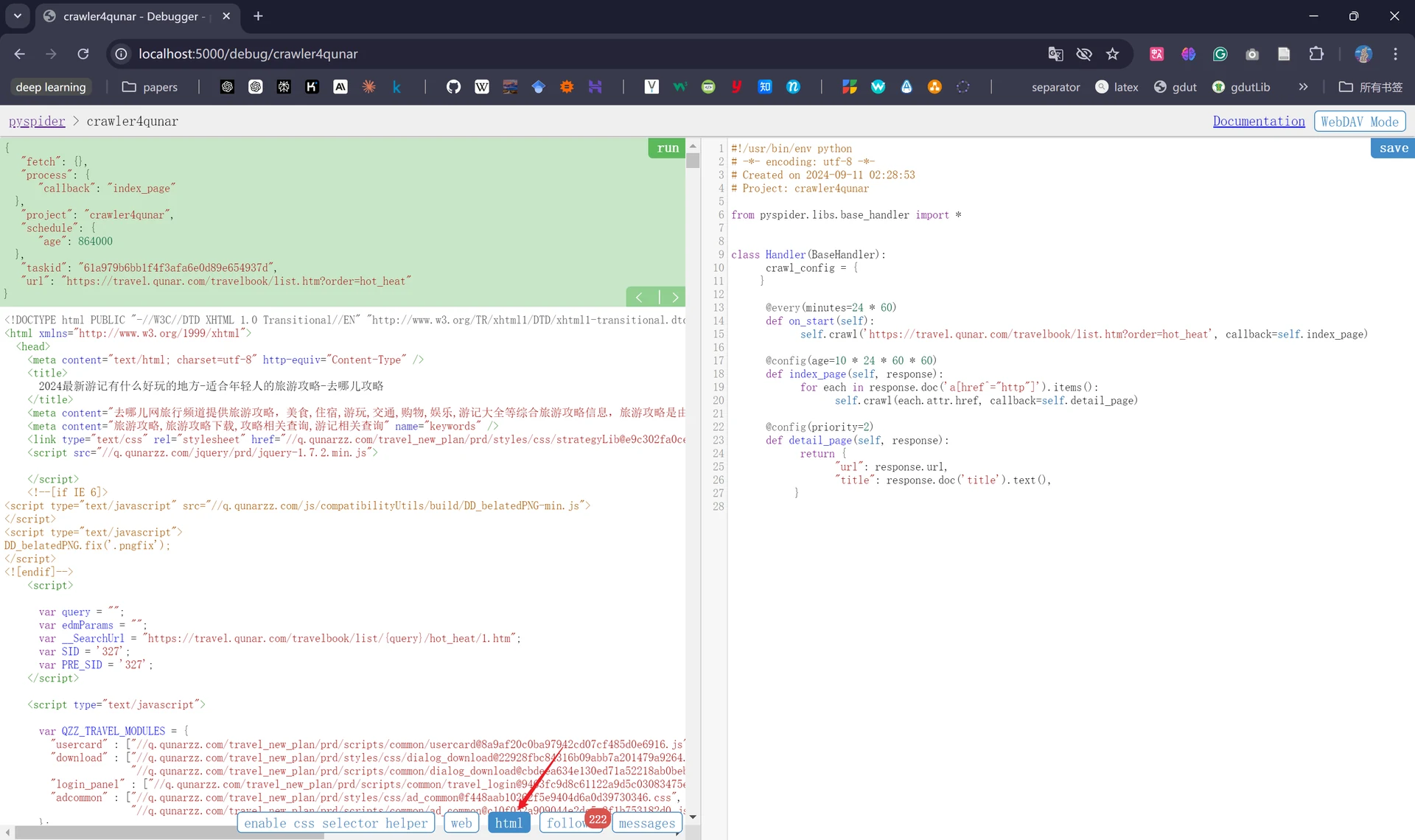
但现在的问题是我们需要爬取的不是所有的222个链接,而只需要旅游攻略详情的页面链接即可,所以此时我们要对爬虫代码里的index_page()方法稍作修改以符合我们的需求(也就是需要修改负责提取链接的CSS选择器.doc()方法)。
我们首先点击“web”切换为网络视图页面,将当前预览页面滑动至任意一篇旅游笔记的标题处,接着点击“enable css selector helper”,然后再点击这篇笔记的标题,我们会发现标题处于被选中状态,上方出现了一个CSS选择器,即当前所选标题对应的CSS选择器,我们可以点击复制将其替换至待修改代码处。
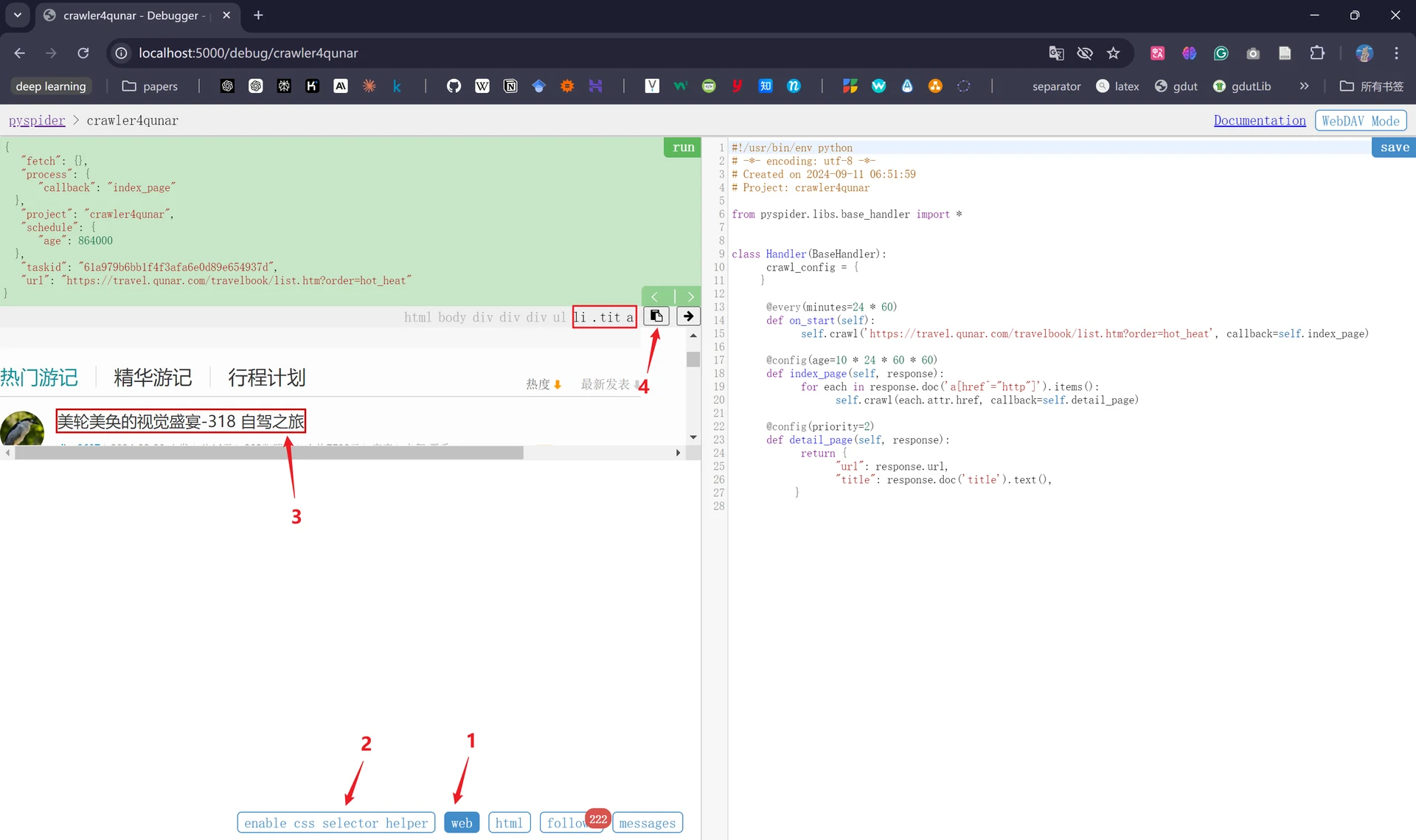
也可以先选中需要修改的代码,点击向右的箭头进行自动替换(不要忘记save!)。
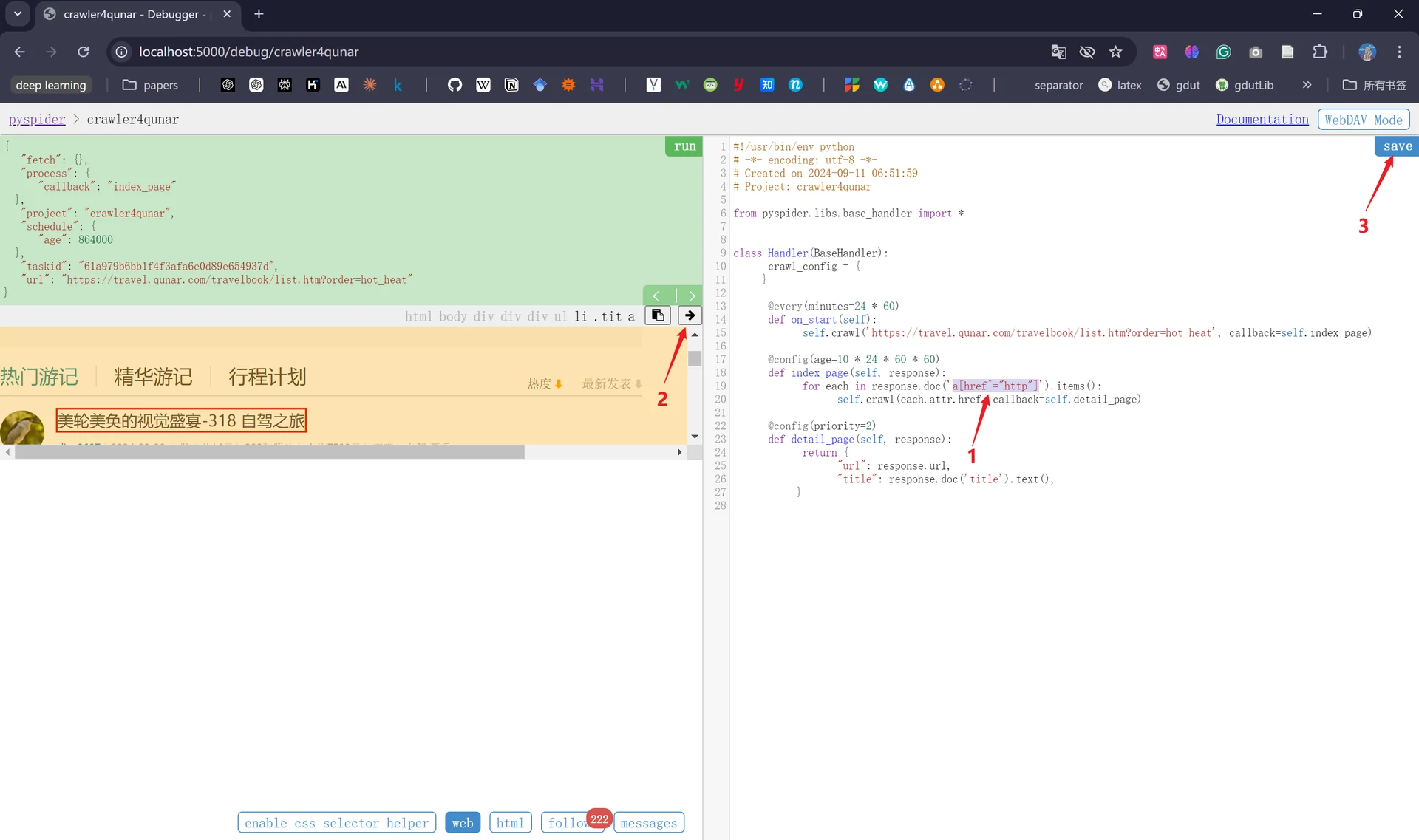
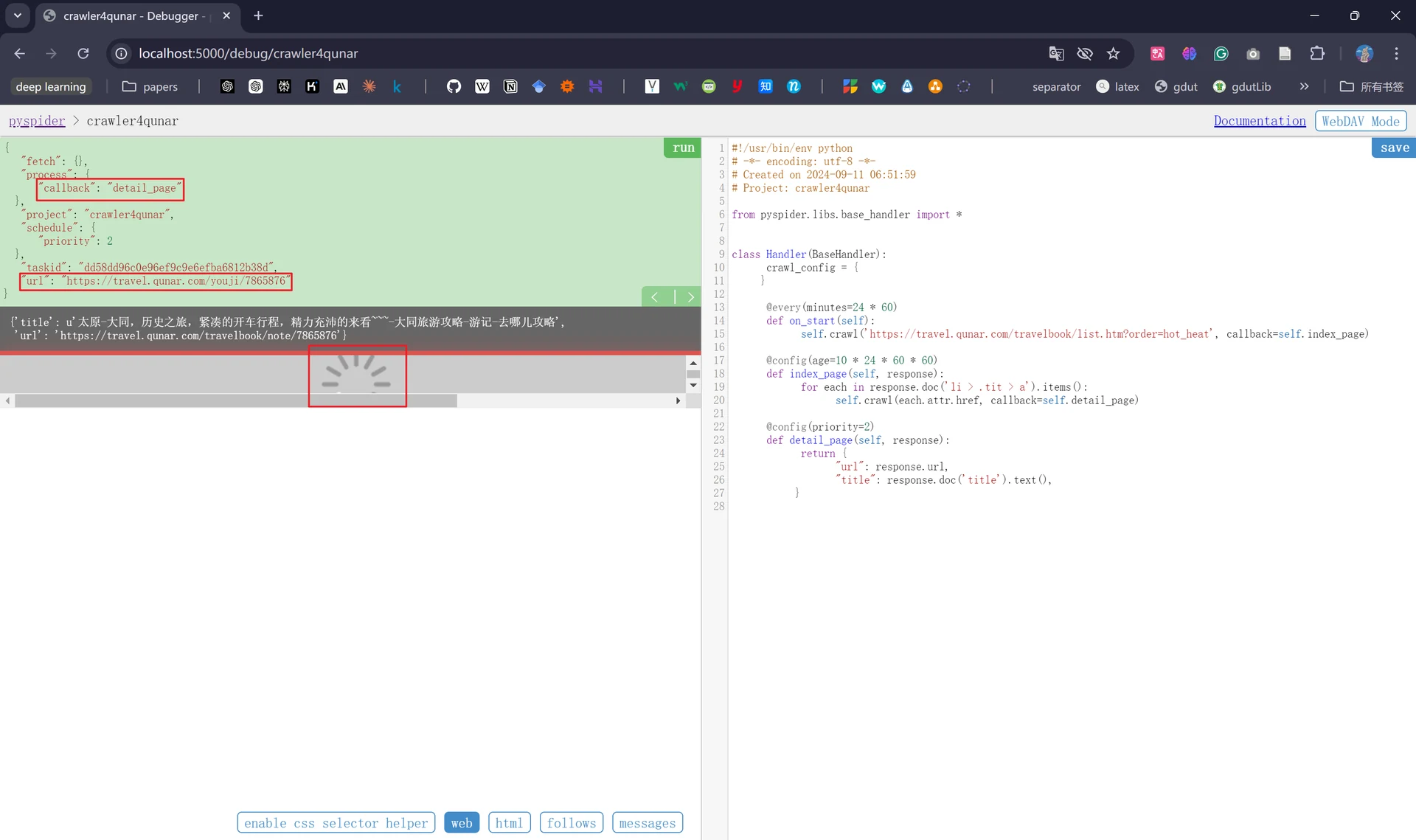
现在我们重新点击“run”,重新调用index_age()方法,会发现此时爬取的链接变成了一页中的10个:
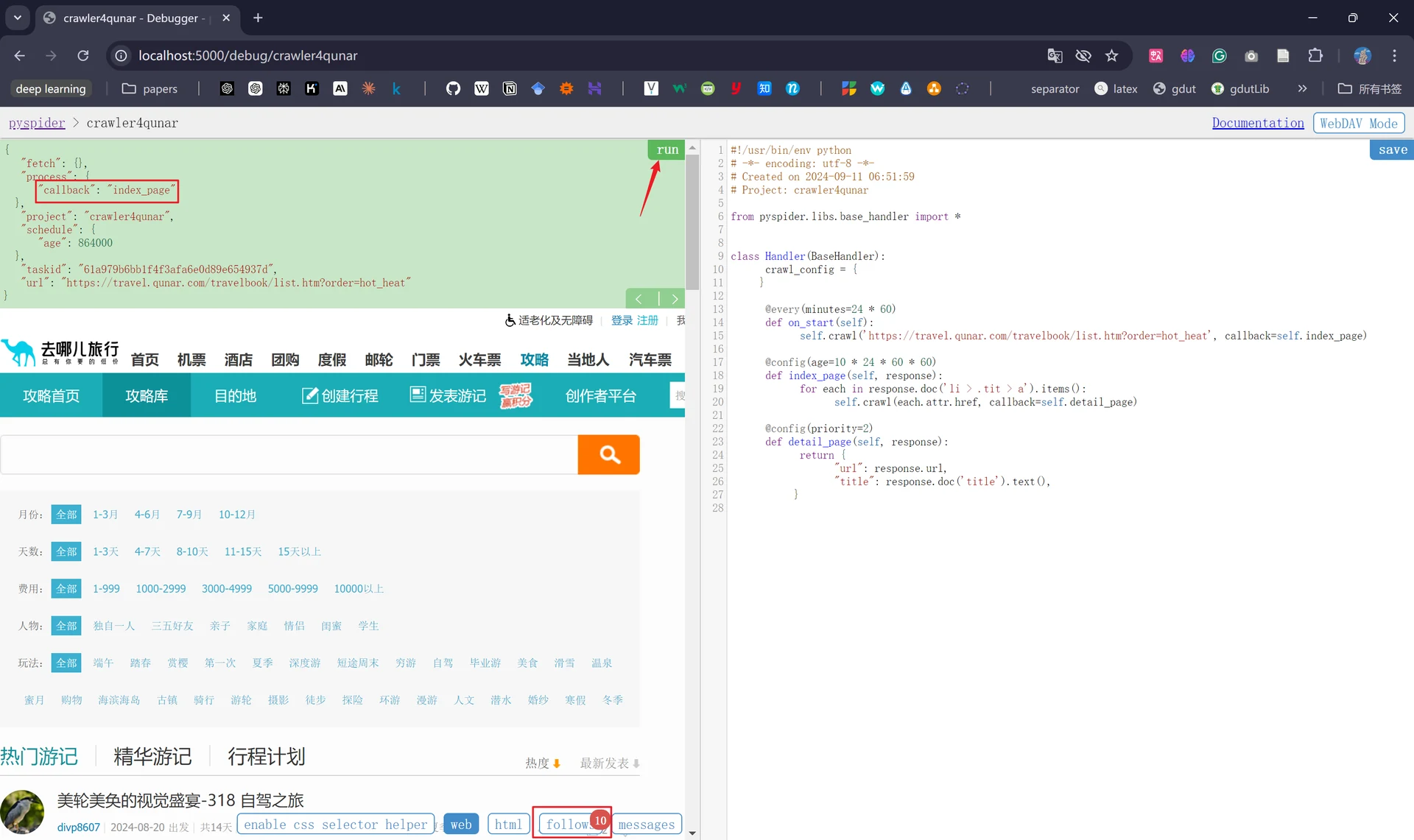
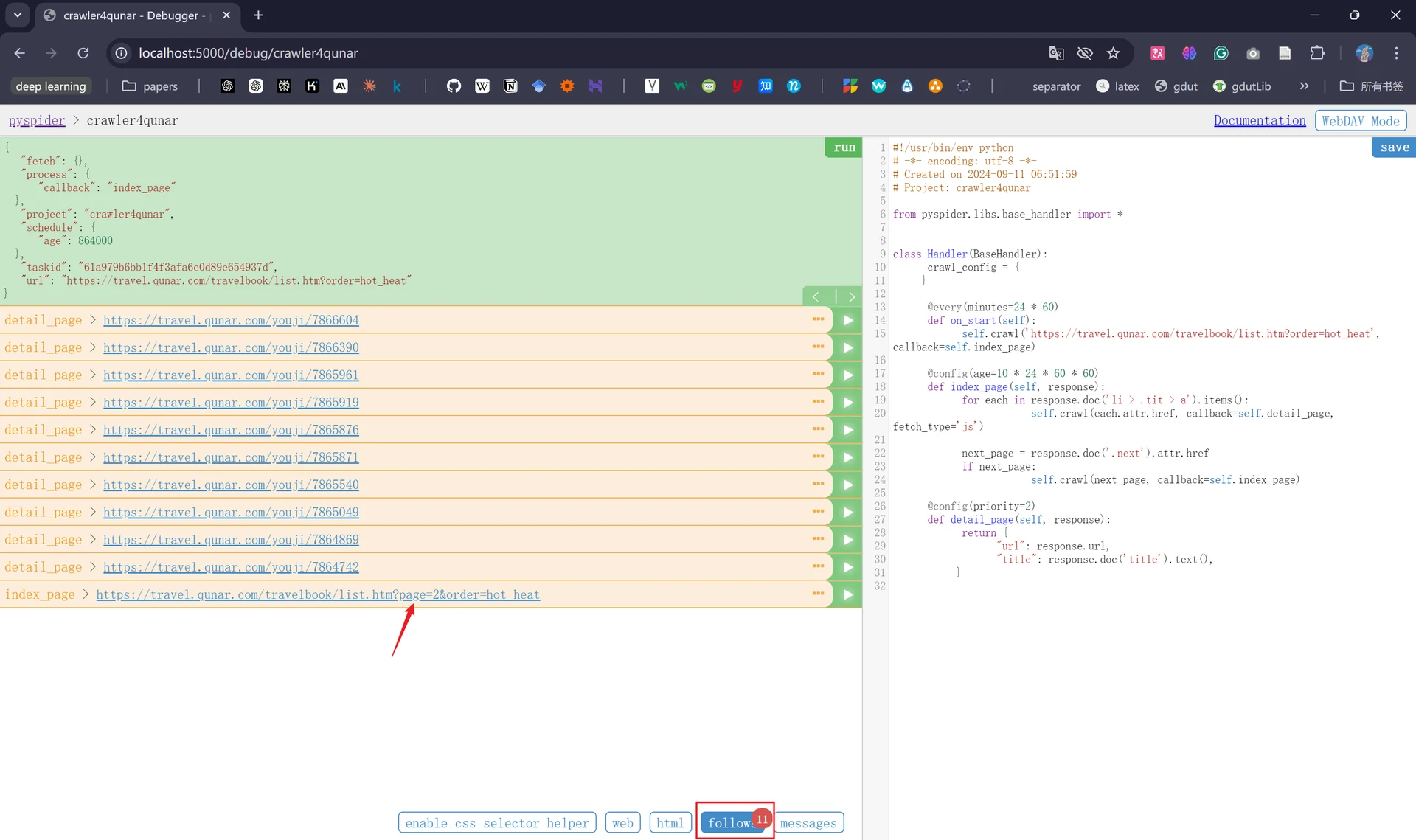
此时我们能发现抓取的链接仅仅只是第一页的10个链接,如果想要抓取更多的后续页面我们还需要在index_page()方法中添加负责获取下一页链接的代码;
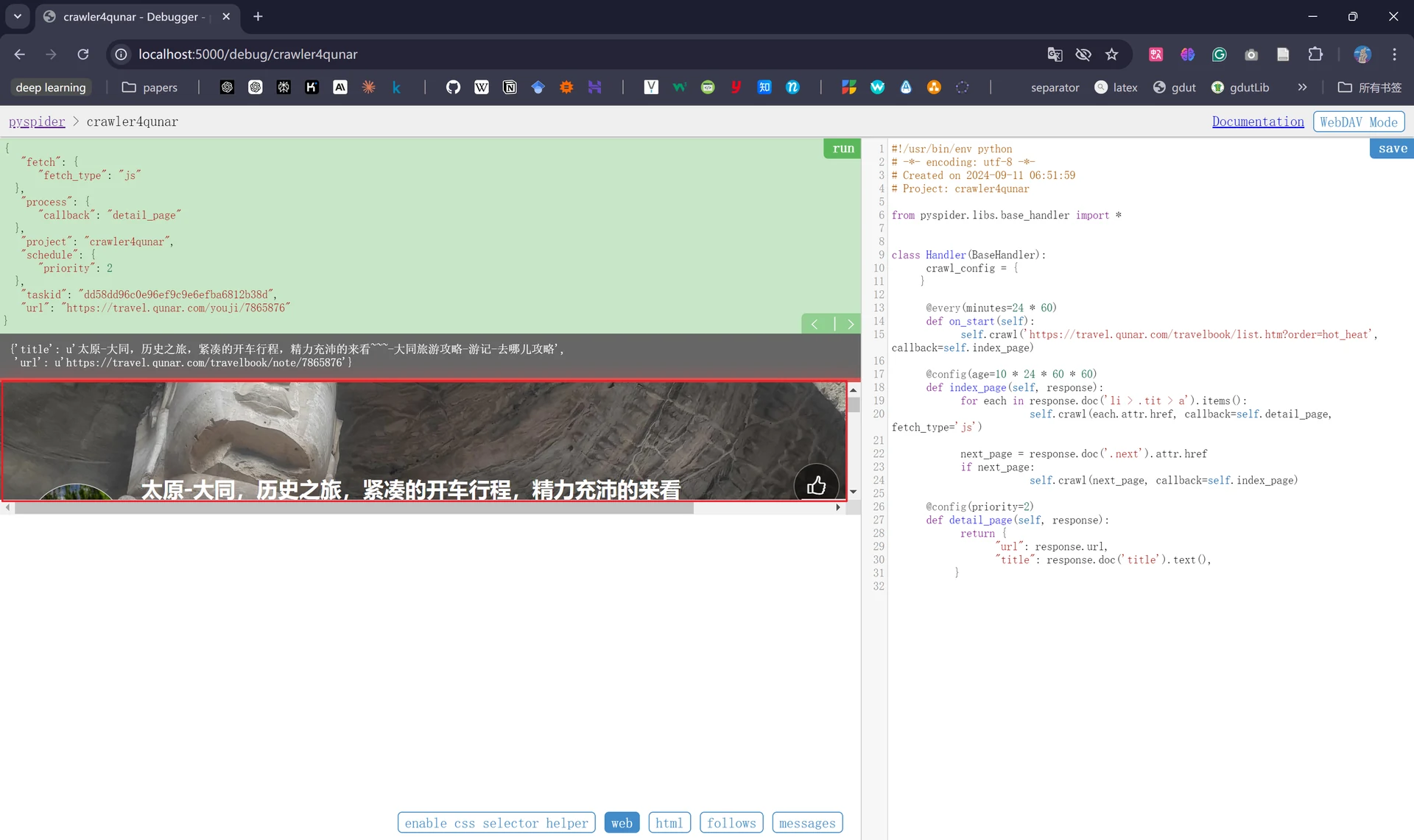
并且如果我们点击第一页任意一条链接的向右箭头并查看web页面时会发现攻略中的图片一直处于加载状态而没有显示出来,这是因为Pyspider在请求页面时默认发送HTTP请求,请求得到的HTML文档中并不包括img节点,我们能在浏览器中看到图片的原因是因为经过了JavaScript处理,所以我们在抓取攻略详情页面的时候需要在index_page()中添加一个PhantomJS参数fetch_type。
经过修改后的index_page()方法的代码如下:
def index_page(self, response):
for each in response.doc('li > .tit > a').items():
self.crawl(each.attr.href, callback=self.detail_page, fetch_type='js')
next_page = response.doc('.next').attr.href
if next_page:
self.crawl(next_page, callback=self.index_page)
修改代码保存后,我们回退重新运行一下,便会发现此时页面图片已经加载出来了,并且爬取链接处出现了下一页的链接:
最后我们修改一下提取详情页信息的detail_page()方法代码,使其能够提取我们想要的内容部分(页面的链接、攻略标题、出行日期、出行天数、人物、攻略正文和封面图片信息)。
def detail_page(self, response):
return {
'url': response.url,
'title': response.doc('#booktitle').text(),
'date': response.doc('.when .data').text(),
'day': response.doc('.howlong .data').text(),
'who': response.doc('.who .data').text(),
'text': response.doc('#b_panel_schedule').text(),
'image': response.doc('.cover_img').attr.src
}
将代码修改完毕后我们重新运行一下,发现已经得到了我们想要的信息:
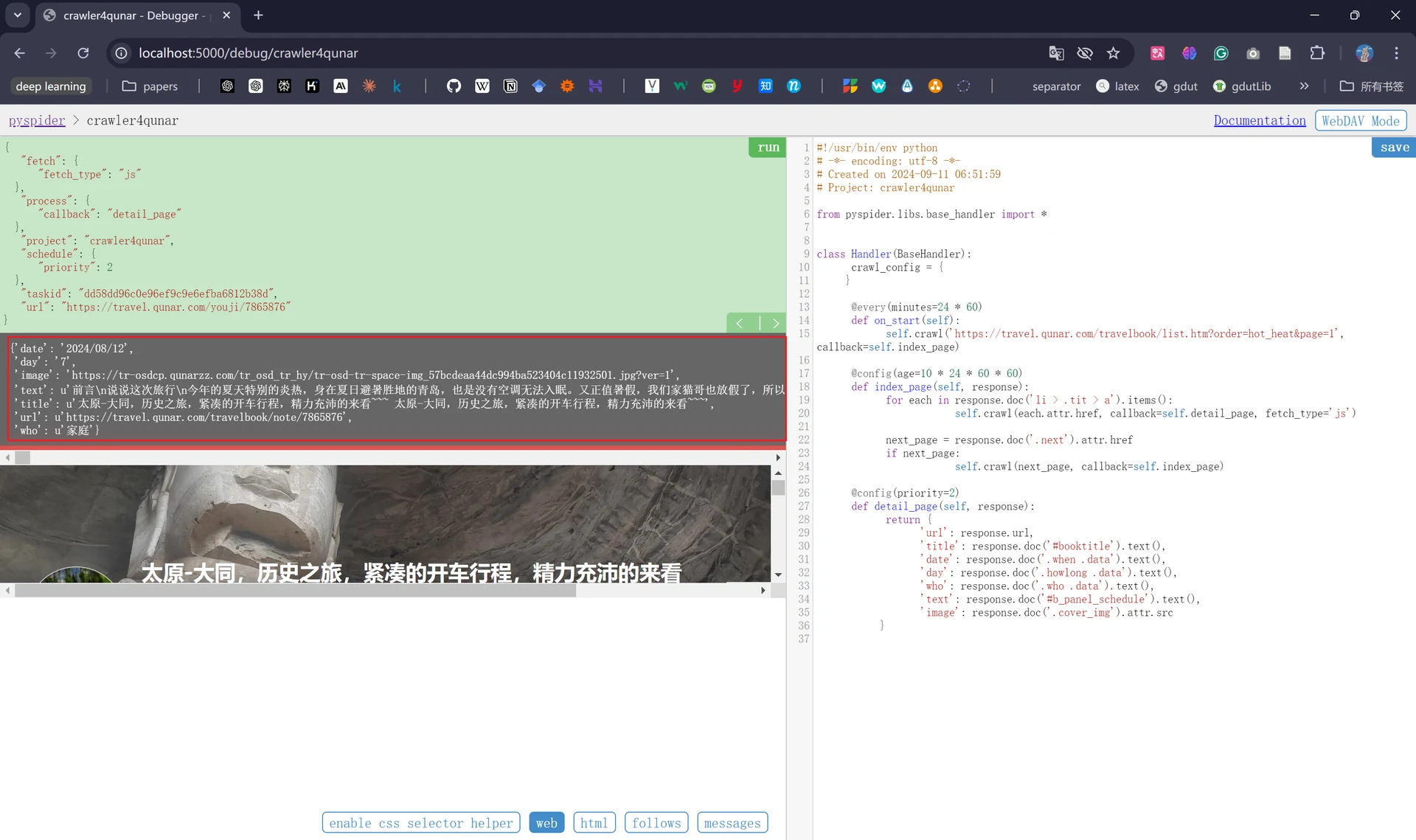
四、启动爬虫进行大规模爬取#
我们点击页面左上角的“pyspider”返回至Pyspider的WebUI dashboard:
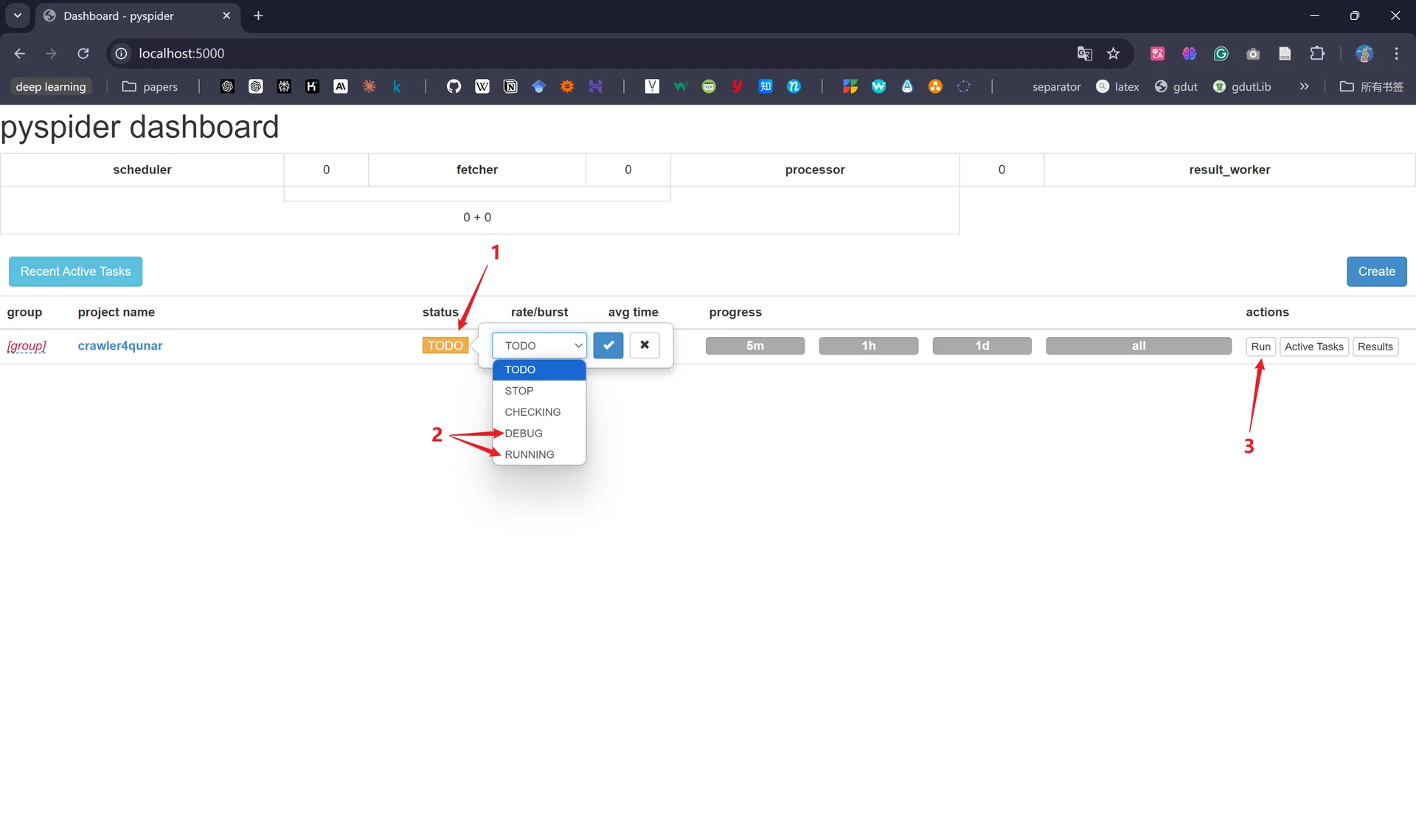
接着将项目的status设置为“DEBUG”或者“RUNNING”,再点击“Run”开始进行爬取:
在dashboard最左侧的“group”是我们定义的项目分组;“rate/burst”代表当前的爬取速率,rate代表1秒内发出多少个请求,burst代表突发速率,表示爬虫在短时间内可以超过速率限制的最大数量,rate和burst设置的越大爬取速率越快,但是被封的概率也越大;“avg time”表示爬取一个页面所花费的平均时间(单位为秒);“process”表示爬虫进度,从左至右依次代表过去5分钟、过去一小时、过去一天和所有任务的总数,蓝色代表等待被执行的请求、绿色代表成功的请求、黄色代表请求失败后等待重试的请求、红色代表失败次数过多而被忽略的请求;“Active Tasks”代表当前活跃的任务;“Results”代表已爬取的结果数据。
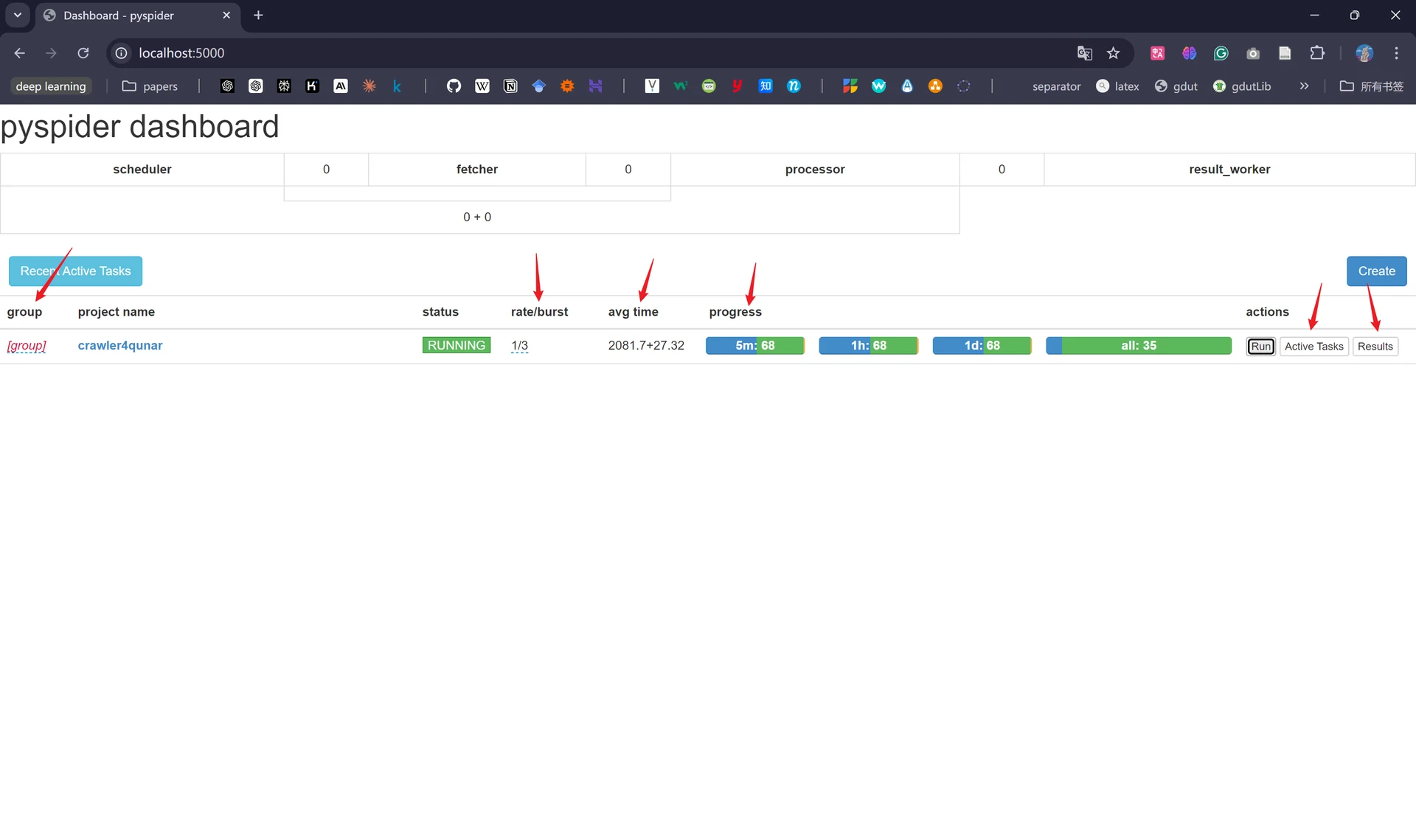
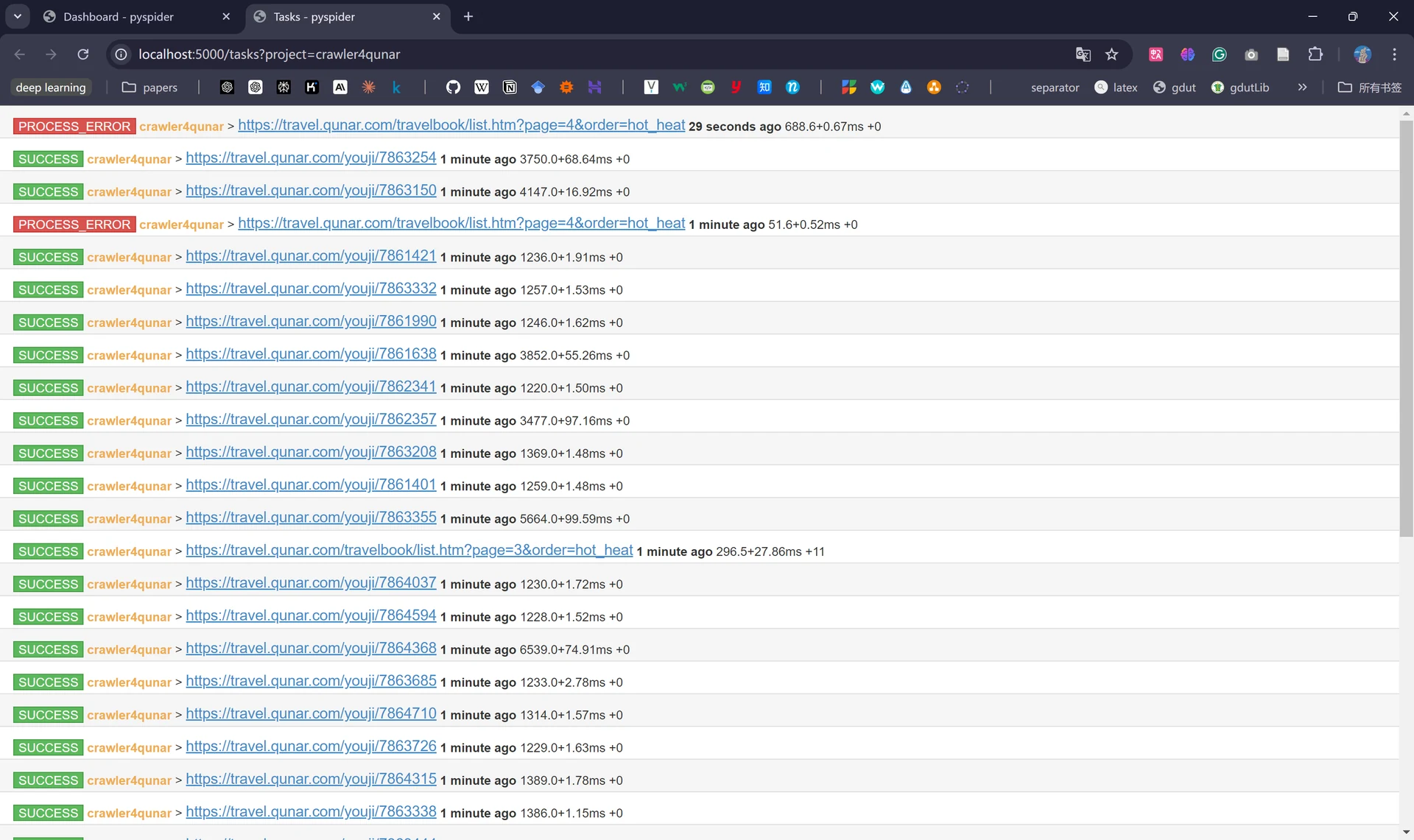
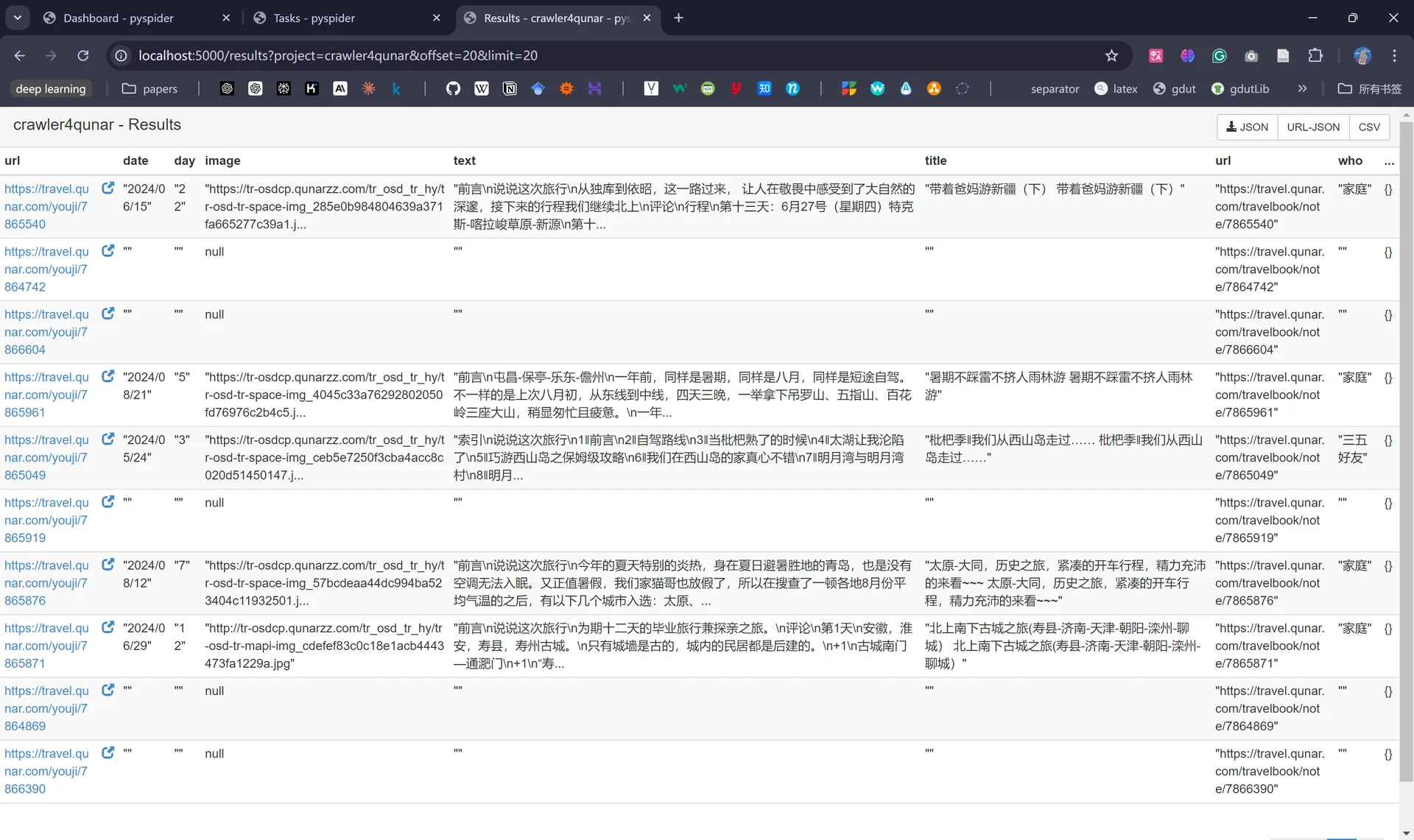
至此我们就已经得到了所需信息的爬取结果了,点击右上角的不同格式可支持导出对应的文件。
五、Pyspider项目总结#
在此次的项目复现中,我们能发现与传统的爬虫方式最大的不同的是,Pyspider为我们提供了一个易于交互的可视化Web UI系统,让我们能够实时逐步地进行编写和调试,并且提供了项目管理、进程监控和结果查看等方式;但是在实践的过程中也有一些状况发生,比如代码的缩进比较鬼畜、web页面的查看大小时常不一、经常需要run多次才能爬取成功等问题,总体来说体验还是不错的,瑕不掩瑜。
Last but not least,让我们在实践过后来简单了解一下Pyspider的架构原理:
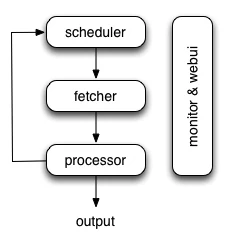
Pyspider的架构主要分为调度器(Scheduler)、抓取器(Fetcher)、处理器(Processor)三个部分,整个进程收到监控器(Monitor)的监控,爬取的结果交由Result Worker(结果处理器)进行处理。
其中Scheduler发起任务调度,Fetcher负责抓取网页内容,Processor负责解析网页内容并将新生成的Request发给Scheduler进行调度,将生成的爬取结果输出保存,具体实现逻辑如下:
-
每个Pyspider项目对应一个Python脚本,脚本中预定义了一个Handler类,该类中含有一个on_start()方法,爬取首先调用on_start()方法生成初始爬取任务,然后发送至Scheduler进行调度;
-
Scheduler将抓取任务分发给Fetcher进行抓取,Fetcher执行抓取动作并得到响应,随后将响应发送给Processor;
-
Processor处理响应并提取出新的URL生成新的抓取任务,然后以消息队列的方式通知Scheduler当前抓取任务的执行情况,并将新的抓取任务发送给Scheduler,如果生成了新的抓取结果,则将其发送至结果队列等待Result Worker处理;
-
Scheduler接收到新的抓取任务并查询数据库,判断其是否是新的抓取任务或者需要retry的任务,如果是的话就继续调度,然后将反馈信息发送回Fetcher进行抓取;
-
重复执行上述操作直到所有的任务全部执行完毕,此时抓取结束;
-
抓取任务结束后,爬虫回调on_finished()方法,我们可以在此方法中定义一系列抓取后处理操作。
给自己挖个坑:择日把某工管院的网页给爬了😈哈哈哈哈哈敬请期待…… https://glxy.gdut.edu.cn/index.htm